Obiettivi | Certificazione | Contenuti | Tipologia | Prerequisiti | Durata e Frequenza | Docenti | Modalità di Iscrizione | Calendario

Il Corso DP-700 Fabric Data Engineer è rivolto a partecipanti che devono progettare e distribuire soluzioni di data engineering su Microsoft Fabric per scenari di enterprise-scale data analytics, lavorando su data loading patterns, data architectures e orchestration processes. Il percorso copre la progettazione di carichi full e incremental, la preparazione dei dati per un dimensional model, e l’implementazione di pipeline di ingest e trasformazione sia batch sia streaming. Vengono approfondite le scelte operative tra Dataflow Gen2, pipelines e notebooks, l’uso di Power Query (M), PySpark, SQL/T-SQL e KQL, oltre alla gestione di data connections, mirroring e integrazioni con OneLake e Real-Time Intelligence. Ampio spazio è dedicato a security & governance (workspace/item access controls, row/column/object/folder-file level security, dynamic data masking, sensitivity labels, endorsement) e alla gestione del ciclo di vita con version control, database projects e deployment pipelines. La parte finale si concentra su monitoring, alerting, troubleshooting e ottimizzazione di performance su Lakehouse, data warehouse, Spark, query e componenti real-time. Il corso contribuisce alla preparazione dell’esame di Certificazione Fabric Data Engineer Associate.
Contattaci ora per ricevere tutti i dettagli e per richiedere, senza alcun impegno, di parlare direttamente con uno dei nostri Docenti (Clicca qui)
oppure chiamaci subito al nostro Numero Verde (800-177596).
Calling from abroad? Reach us at +39 02 87168254.
Obiettivi del corso
Di seguito una sintesi degli obiettivi principali del corso Corso Fabric Data Engineer DP-700:
- Progettare data loading patterns (full/incremental) e preparare dati per dimensional modeling in Fabric.
- Ingestire e trasformare dati batch con Dataflow Gen2, pipelines e notebooks usando Power Query (M), PySpark, SQL/T-SQL e KQL.
- Progettare e implementare ingest/processing streaming con Eventstream, Spark Structured Streaming, KQL e windowing functions.
- Implementare security & governance (workspace/item controls, fine-grained security, dynamic data masking, sensitivity labels, endorsement).
- Monitorare, risolvere errori e ottimizzare performance su Lakehouse, warehouse, Spark, pipelines e query.
Certificazione del corso
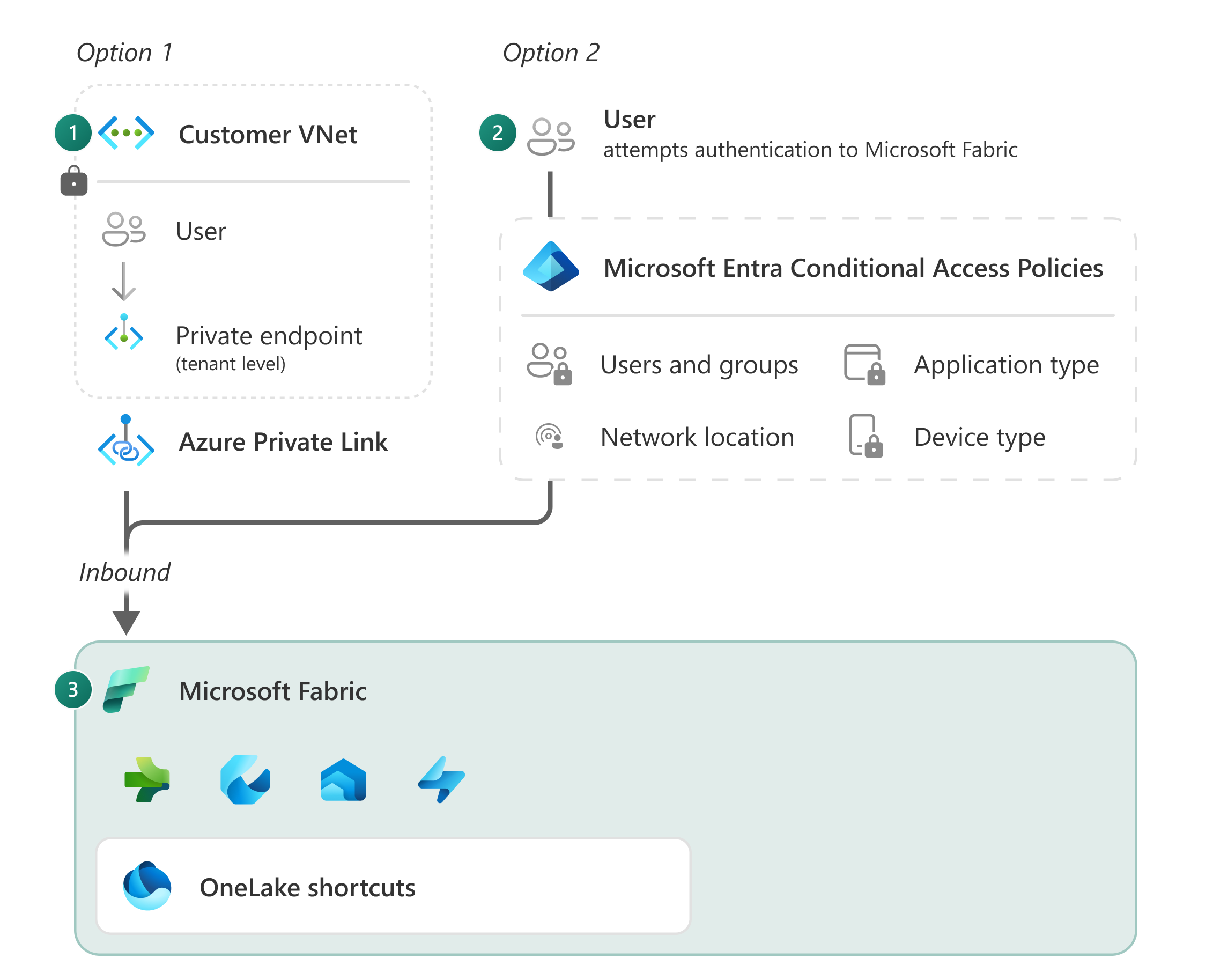
Esame DP-700 Fabric Data Engineer Associate; Questo esame verifica le competenze del candidato nell’implementare e gestire una soluzione di data engineering in Microsoft Fabric su tre macro-aree: implementazione/gestione, ingest/transform e monitor/optimize. I topics testati includono la configurazione delle workspace settings (Spark, domain, OneLake, data workflow), la gestione del ciclo di vita con version control, database projects e deployment pipelines, e l’implementazione di security & governance con controlli di accesso a livello workspace e item, row/column/object/folder-file level security, dynamic data masking, sensitivity labels, endorsement e workspace logging, inclusa la sicurezza di OneLake.
Sul fronte ingest e trasformazione, l’esame copre la progettazione di modelli di caricamento full e incremental, la preparazione dei dati per un dimensional model, e la progettazione di un modello di caricamento per dati streaming. Per i workload batch valuta la scelta di un data store appropriato, la selezione tra Dataflows, notebooks, KQL e T-SQL per la trasformazione, la gestione di data connections, l’implementazione del mirroring, l’ingest con pipelines e con integrazione continua da OneLake, e le trasformazioni con Power Query (M), PySpark, SQL e KQL, incluse denormalization, group/aggregate e gestione di dati duplicati, mancanti o in ritardo.
Per lo streaming include la scelta del motore, le opzioni tra storage nativo/mirroring/links in Real-Time Intelligence, processing con Eventstream, Spark Structured Streaming e KQL, oltre a windowing functions. Chiude con monitoraggio (ingest/transform/semantic model refresh, alerting), troubleshooting di errori (pipelines, dataflows, notebooks, Eventhouse/Eventstream, T-SQL, OneLake shortcuts) e ottimizzazione (Lakehouse tables, pipelines, warehouse, Eventstream/Eventhouse, Spark e query performance).
Contenuti del corso
Implement and manage a Fabric analytics solution
- Configure workspace settings for Spark, domains, OneLake, and data workflow
- Enable and use workspace logging for traceability and operational auditing
- Organize Fabric items (lakehouse/warehouse/eventhouse/notebooks/pipelines) with dependency awareness
- Apply OneLake security concepts and data estate organization principles
- Define standards for naming, ownership, and asset lifecycle (draft → promoted → certified)
- Establish operational responsibilities across data engineer, platform admin, and analytics teams
Lifecycle management and delivery
- Set up version control for workspaces and Fabric items
- Use database projects for SQL/T-SQL artifacts and change tracking
- Configure deployment pipelines (dev/test/prod) with controlled promotions
- Manage releases across notebooks, pipelines, dataflows, and SQL artifacts with dependency alignment
- Design rollback and hotfix strategies for production incidents
- Implement repeatable deployment patterns and environment configuration consistency
Security and governance
- Configure workspace-level access controls and admin roles
- Apply item-level access controls and secure sharing patterns
- Implement fine-grained security: row-level, column-level, object-level, folder/file-level security
- Configure dynamic data masking where appropriate and validate impact on analytics
- Apply sensitivity labels and understand downstream effects on sharing and compliance
- Use endorsement (promoted/certified) to manage trust and governance signals
Orchestration and process design
- Choose the right tool per workload: Dataflow Gen2 vs pipelines vs notebooks
- Build orchestration with parameters, reusable templates, and dynamic expressions
- Implement scheduling and event-based triggers (where applicable)
- Design dependency chains, retries, failure handling, and idempotent re-runs
- Separate orchestration patterns for batch vs streaming workloads
- Create operational runbooks for execution monitoring and incident response
Data loading patterns and modeling readiness
- Design full load vs incremental load patterns and choose the correct approach per source
- Prepare data for dimensional modeling (staging, conforming dimensions, fact shaping)
- Define strategies for late-arriving data, reprocessing, and backfills
- Handle duplicates, missing values, and out-of-range data with deterministic rules
- Establish data quality checks and acceptance criteria for analytics consumption
- Decide the target store pattern: lakehouse tables vs warehouse objects vs eventhouse structures
Ingest and transform batch data
- Select the appropriate storage target (lakehouse/warehouse) based on query patterns and SLAs
- Create and manage data connections and reusable ingestion configurations
- Implement ingestion with pipelines and continuous integration patterns with OneLake
- Use Power Query (M) for shaping, standardization, and enrichment where it fits
- Use PySpark for scalable transforms and complex processing
- Use SQL/T-SQL and KQL where they provide the best performance/maintainability trade-off
Ingest and transform streaming data (Real-Time Intelligence)
- Select the streaming engine based on throughput/latency and operational constraints
- Choose between native storage, mirroring, or links in Real-Time Intelligence
- Distinguish accelerated vs non-accelerated links and their use cases
- Implement processing with Eventstream and event flow design
- Implement Spark Structured Streaming for advanced streaming transformations
- Use KQL for real-time analytics scenarios and apply windowing functions for time-based aggregations
Monitoring, troubleshooting, and optimization
- Monitor ingestion, transformation, and semantic model refresh with actionable alerting
- Troubleshoot failures in pipelines, dataflows, notebooks, and T-SQL execution
- Diagnose streaming issues in Eventhouse/Eventstream and ingestion bottlenecks
- Troubleshoot OneLake shortcuts issues and connectivity/data access problems
- Optimize performance: lakehouse table design, warehouse objects, Spark performance, and query efficiency
- Track technical KPIs (latency, throughput, failure rate, cost drivers) and apply continuous improvements
Tipologia
Corso di Formazione con Docente
Docenti
I docenti sono Istruttori Autorizzati Microsoft e in altre tecnologie IT, con anni di esperienza pratica nel settore e nella Formazione.
Infrastruttura laboratoriale
Per tutte le tipologie di erogazione, il Corsista può accedere alle attrezzature e ai sistemi presenti nei Nostri laboratori o direttamente presso i data center del Vendor o dei suoi provider autorizzati in modalità remota. Ogni partecipante dispone di un accesso per implementare le varie configurazioni avendo così un riscontro pratico e immediato della teoria affrontata. Ecco di seguito alcuni scenari tratti dalle attività laboratoriali:
Dettagli del corso
Prerequisiti
- Si consiglia la partecipazione al Corso Azure Data Fundamentals DP-900
Durata del corso
- Durata Intensiva 4gg;
Frequenza
Varie tipologie di Frequenza Estensiva ed Intensiva.
Date del corso
- Corso Fabric Data Engineer (Formula Intensiva) – 15/10/2026 – 09:00 – 17:00
Modalità di iscrizione
Le iscrizioni sono a numero chiuso per garantire ai tutti i partecipanti un servizio eccellente.
L’iscrizione avviene richiedendo di essere contattati dal seguente Link, o contattando la sede al numero verde 800-177596 o inviando una richiesta all’email [email protected].