Obiettivi | Certificazione | Contenuti | Tipologia | Prerequisiti | Durata e Frequenza | Docenti | Modalità di Iscrizione | Calendario

Il Corso DCAI – Implementing Cisco Data Center AI Infrastructure è parte del percorso Cisco CCNP Data Center. Il corso DCAI è dedicato ai professionisti che devono progettare, implementare, supportare, monitorare e ottimizzare infrastrutture Data Center in grado di sostenere workload AI/ML ad alte prestazioni. Il corso fornisce ai Partecipanti le competenze necessarie per comprendere l’impatto delle applicazioni di Artificial Intelligence, Machine Learning e Generative AI sull’architettura, sulla rete, sul compute, sullo storage e sulle operations dei moderni ambienti Cisco Data Center. Durante il corso vengono trattati i principali componenti tecnologici e architetturali legati alle infrastrutture AI, tra cui AI/ML clusters, Jupyter Notebook, Python, Generative AI, RAG, open source GPT models, AI workload placement, high-performance Ethernet fabrics, RDMA, RoCE, ECN, PFC, lossless fabrics, Cisco Nexus Dashboard Insights, NDFC, telemetry, monitoring, log correlation e troubleshooting avanzato. Il programma affronta inoltre le tematiche relative a compute resources, AI-enabling hardware, virtual resources, storage resources, optical e copper technologies, connectivity models, Layer 2 e Layer 3 protocols, data preparation, data performance, governance, compliance, security e sustainability applicate agli ambienti AI. Particolare attenzione viene dedicata alla gestione operativa delle infrastrutture AI-enabled, con focus su monitoraggio dei flussi AI/ML, analisi delle performance, individuazione dei colli di bottiglia, risoluzione dei problemi comuni nelle fabric AI/ML e utilizzo di strumenti come Splunk e Cisco Nexus Dashboard Insights per migliorare visibilità, controllo e affidabilità dell’ambiente. Il Corso contribuisce alla preparazione dell’esame di Certificazione CCNP Data Center DCAI (Esame 300-640).
Contattaci ora per ricevere tutti i dettagli e per richiedere, senza alcun impegno, di parlare direttamente con uno dei nostri Docenti (Clicca qui)
oppure chiamaci subito al nostro Numero Verde (800-177596).
Calling from abroad? Reach us at +39 02 87168254.
Obiettivi del corso
Di seguito una sintesi degli obiettivi principali del Corso DCAI – Implementing Cisco Data Center AI Infrastructure:
- Comprendere i concetti fondamentali di AI, Machine Learning, Deep Learning, Generative AI e il loro impatto sulle infrastrutture Data Center.
- Progettare e valutare architetture per AI/ML workloads, includendo compute, storage, networking, interoperability e workload placement.
- Analizzare tecnologie di rete per ambienti AI ad alte prestazioni, tra cui RDMA, RoCE, ECN, PFC, high-performance Ethernet fabrics e lossless fabrics.
- Utilizzare strumenti come Jupyter Notebook, Cisco Nexus Dashboard Insights, NDFC, telemetry e log analysis per monitoring, operations e troubleshooting.
- Implementare e gestire soluzioni basate su RAG, open source GPT models, AI clusters, data preparation e AI infrastructure optimization.
Certificazione del corso
Esame 300-640 DCAI Cisco Certified Specialist – Data Center AI Infrastructure;
Esame Parte della Certificazione CCNP Data Center. Questo esame valuta le competenze del candidato nella progettazione, implementazione, gestione e ottimizzazione di infrastrutture Data Center dedicate a workload AI/ML. Il superamento dell’esame consente di ottenere la certificazione Cisco Certified Specialist – Data Center AI Infrastructure e soddisfa il requisito concentration per il percorso Cisco CCNP Data Center. L’esame verifica la capacità dell’esaminato di comprendere i fondamenti di Artificial Intelligence, Machine Learning, Deep Learning e Generative AI, con attenzione all’impatto delle applicazioni AI sulle architetture Data Center. Sono testate competenze relative ad AI/ML clusters, modelli pre-trained, fine-tuning, optimization, RAG, open source GPT models e utilizzo di strumenti come Jupyter Notebook per attività tecniche e operative. Una parte centrale riguarda la progettazione dell’infrastruttura per workload AI, includendo compute resources, AI-enabling hardware, virtual resources, storage resources, workload placement, interoperability, data preparation e data performance. L’esame copre inoltre tecnologie di networking ad alte prestazioni, tra cui RDMA, RoCE, high-performance Ethernet fabrics, lossless fabrics, ECN, PFC, connectivity models, Layer 2 e Layer 3 protocols applicati ad ambienti AI/ML. Il candidato deve dimostrare competenze anche su monitoring, operations e troubleshooting di infrastrutture AI-enabled, con focus su Cisco Nexus Dashboard Insights, NDFC, telemetry, congestion visibility, log correlation, analisi dei flussi AI/ML e risoluzione dei problemi comuni nelle fabric AI/ML.
Contenuti del corso
Fundamentals of AI
- Core concepts of Artificial Intelligence, Machine Learning, and Deep Learning
- Differences between traditional AI approaches and modern AI systems
- Main AI techniques and their application in enterprise environments
- Role of AI in automation, analytics, and decision support
- Impact of AI adoption on modern Data Center infrastructure
Generative AI
- Key concepts of Generative AI and foundation models
- Differences between traditional AI and generative AI methodologies
- Use cases of Generative AI in IT operations and infrastructure management
- Challenges related to accuracy, bias, hallucination, and governance
- Future trends in Generative AI for enterprise environments
AI Use Cases
- Practical AI use cases in network management and Data Center operations
- Use of AI for intelligent automation and predictive analytics
- Application of AI for anomaly detection and operational optimization
- AI-driven support for monitoring, troubleshooting, and security
- Evaluation of business and technical value in AI-enabled workflows
AI-ML Clusters and Models
- Architecture and components of AI/ML clusters
- Basic management principles for AI/ML cluster environments
- Use of pre-trained Machine Learning models
- Model acquisition, fine-tuning, optimization, and deployment concepts
- Operational considerations for AI/ML model usage in Data Center environments
AI Toolset—Jupyter Notebook
- Use of Jupyter Notebook for AI and infrastructure-related tasks
- Execution of Python-based workflows for AI-assisted operations
- Use of Generative AI to support network operations and automation
- Development of scripts and technical workflows in notebook environments
- Productivity enhancement through AI models and interactive toolsets
AI Infrastructure
- Essential components of modern AI infrastructure
- Relationship between AI workloads and Data Center architecture
- Infrastructure requirements for supporting AI/ML applications
- Design considerations for compute, network, and storage resources
- Operational impact of AI workloads on Data Center environments
AI Workloads Placement and Interoperability
- Strategies for effective AI workload placement
- Interoperability requirements across AI infrastructure components
- Evaluation of compute, storage, and network dependencies
- Optimization of workload distribution for performance and efficiency
- Infrastructure planning for scalable AI/ML environments
AI Policies
- Governance frameworks for enterprise AI systems
- Compliance standards and policy considerations for AI deployments
- Security and operational policies for AI-enabled infrastructure
- Risk management related to AI usage and infrastructure exposure
- Alignment between AI policies, business requirements, and IT operations
AI Sustainability
- Principles of sustainable AI infrastructure
- Environmental and economic considerations for AI deployments
- Optimization of resource consumption in AI/ML environments
- Efficiency strategies for compute, storage, and networking resources
- Sustainability impact of AI workload design and infrastructure decisions
AI Infrastructure Design
- Design principles for Data Center infrastructure supporting AI workloads
- Evaluation of architecture options for AI/ML applications
- Cost, performance, efficiency, and scalability considerations
- Infrastructure design decisions for AI-enabled environments
- Alignment of Data Center design with AI workload requirements
Key Network Challenges and Requirements for AI Workloads
- Network requirements driven by AI/ML application behavior
- Performance challenges related to throughput, latency, and congestion
- Impact of distributed AI processing on Data Center networks
- Requirements for reliable and scalable AI workload connectivity
- Network design considerations for AI training and inference workloads
AI Transport
- Role of transport technologies in AI/ML Data Center workloads
- Use of optical and copper technologies for high-performance connectivity
- Transport requirements for large-scale AI data movement
- Performance considerations for AI/ML traffic patterns
- Selection of transport options based on workload and infrastructure needs
Connectivity Models
- Network connectivity models for AI/ML infrastructure
- Design patterns for connecting compute, storage, and network resources
- Connectivity requirements for AI clusters and distributed processing
- Evaluation of scalability, resiliency, and performance in connectivity models
- Integration of connectivity design into Data Center AI architectures
AI Network
- Network design principles for AI/ML workload environments
- Role of Layer 2 and Layer 3 protocols in AI infrastructure
- Network considerations for fog computing and distributed AI processing
- Optimization of network behavior for AI training and inference
- Design of dedicated networks for AI/ML workloads
Architecture Migration to AI/ML Network
- Migration strategies toward dedicated AI/ML network architectures
- Assessment of existing Data Center infrastructure for AI readiness
- Planning of network changes to support AI workload requirements
- Transition from traditional network designs to AI-optimized designs
- Risk reduction during migration to AI-enabled infrastructure
Application-Level Protocols
- Role of application-level protocols in AI/ML infrastructure
- Protocol requirements for distributed AI workloads
- Interaction between applications, data flows, and network behavior
- Impact of application communication patterns on infrastructure design
- Considerations for performance, reliability, and scalability
High-Throughput Converged Fabrics
- Architecture of high-throughput converged Ethernet fabrics
- Features required to support AI/ML traffic at scale
- Fabric design considerations for high-performance Data Centers
- Support for compute, storage, and AI workload convergence
- Operational considerations for converged AI infrastructure fabrics
Building Lossless Fabrics
- Principles of lossless fabric design for AI/ML workloads
- Use of RDMA and RoCE in high-performance Data Center networks
- Network mechanisms required to reduce packet loss and congestion
- QoS tools for building reliable AI-ready fabrics
- Design considerations for performance-sensitive AI applications
Congestion Visibility
- Use of congestion visibility tools in AI/ML fabrics
- Monitoring of traffic behavior and network congestion
- Role of ECN and PFC in congestion management
- Use of Cisco Nexus Dashboard Insights for congestion monitoring
- Analysis of how AI/ML application stages affect infrastructure performance
Data Preparation for AI
- Core steps of the data preparation process for AI workloads
- Challenges related to data quality, structure, and readiness
- Techniques for preparing data for AI/ML processing
- Impact of data preparation on AI model performance
- Relationship between data lifecycle and AI infrastructure requirements
AI/ML Workload Data Performance
- Analysis of data performance requirements for AI/ML workloads
- Monitoring of AI/ML traffic flows and workload behavior
- Use of Cisco Nexus Dashboard Insights for data flow visibility
- Identification of performance bottlenecks in AI-enabled environments
- Optimization of infrastructure for AI/ML data movement
AI-Enabling Hardware
- Role of specialized hardware in AI workload acceleration
- Hardware requirements for reducing AI training times
- Processing needs of AI, Machine Learning, and Deep Learning tasks
- Infrastructure impact of GPU and accelerator-based systems
- Evaluation of hardware choices for AI-enabled Data Centers
Compute Resources
- Compute requirements for running AI/ML solutions
- Role of servers, accelerators, and processing resources in AI infrastructure
- Resource planning for training, inference, and distributed AI workloads
- Performance considerations for compute-intensive AI tasks
- Operational management of compute resources in AI environments
Compute Resource Solutions
- Existing compute solutions for AI/ML infrastructure
- Evaluation of Cisco Data Center compute options for AI workloads
- Integration of compute platforms into AI-enabled architectures
- Scalability and performance considerations for compute resource planning
- Operational considerations for managing AI compute environments
Virtual Resources
- Virtual infrastructure options for AI/ML deployments
- Considerations for deploying AI workloads in virtualized environments
- Impact of virtualization on performance, flexibility, and operations
- Resource allocation and isolation for AI workloads
- Evaluation of virtual resources within Data Center AI architectures
Storage Resources
- Data storage strategies for AI/ML environments
- Storage protocols and their role in AI infrastructure
- Software-defined storage considerations for AI workloads
- Performance requirements for AI data access and movement
- Integration of storage resources into AI-enabled Data Center designs
Setting Up AI Cluster
- Steps for setting up an AI cluster environment
- Configuration of infrastructure components for AI/ML workloads
- Use of NDFC to configure fabrics optimized for AI/ML
- Validation of AI cluster readiness and connectivity
- Operational considerations for AI cluster deployment
Deploy and Use Open Source GPT Models for RAG
- Deployment of open source GPT models for technical use cases
- Use of Retrieval-Augmented Generation (RAG) for network engineering tasks
- Integration of local GPT models with infrastructure-related data
- Application of RAG to improve contextual accuracy and response relevance
- Operational considerations for using GPT models in Data Center environments
AI Infrastructure Operations and Monitoring
- Day-2 operations for AI-enabled Data Center infrastructure
- Monitoring of AI/ML workloads, traffic flows, and infrastructure health
- Use of telemetry, log analysis, and operational visibility tools
- Detection of anomalies and performance degradation
- Operational optimization of AI infrastructure environments
Troubleshooting AI Infrastructure
- Troubleshooting methodology for AI-enabled Data Center environments
- Use of log correlation and telemetry analysis to diagnose issues
- Identification of performance, network, compute, and storage problems
- Advanced troubleshooting techniques for AI/ML infrastructure
- Resolution of issues affecting uptime, performance, and workload stability
Troubleshoot Common Issues in AI/ML Fabric
- Diagnosis of common issues in AI/ML network fabrics
- Analysis of congestion, packet loss, latency, and performance degradation
- Troubleshooting of RoCE, RDMA, ECN, and PFC behavior
- Use of monitoring tools to identify root causes in AI/ML fabrics
- Remediation strategies for maintaining stable AI workload performance
Attività Laboratoriali
- AI Toolset—Jupyter Notebook
- AI/ML Workload Data Performance
- Setting Up AI Cluster
- Deploy and Use Open Source GPT Models for RAG
- Troubleshoot Common Issues in AI/ML Fabric
Tipologia
Corso di Formazione con Docente
Docenti
I docenti sono Istruttori accreditati CISCO e certificati in altre tecnologie IT, con anni di esperienza pratica nel settore e nella Formazione.
Infrastruttura laboratoriale
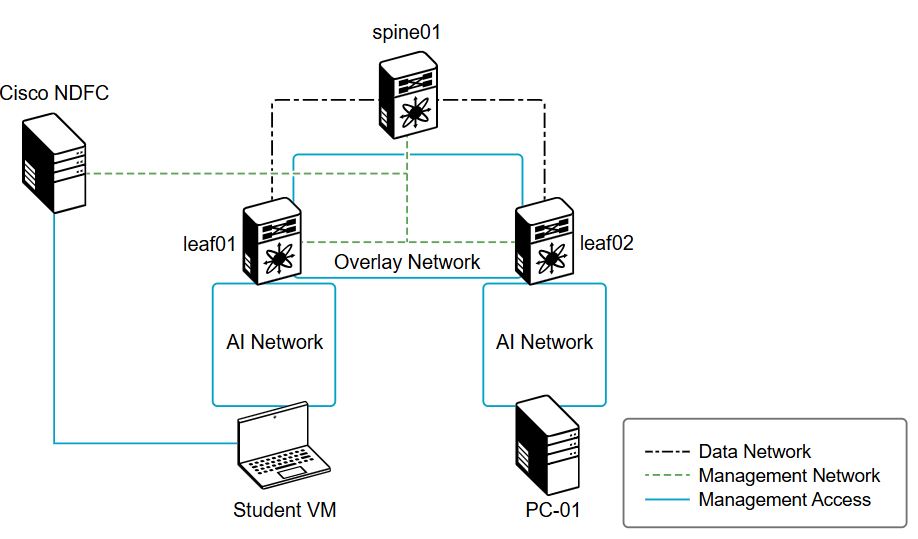
Per tutte le tipologie di erogazione, il Corsista può accedere alle attrezzature e ai sistemi reali Cisco presenti nei Nostri laboratori o direttamente presso i data center Cisco in modalità remota. Ogni partecipante dispone di un accesso per implementare le varie configurazioni avendo così un riscontro pratico e immediato della teoria affrontata. Ecco di seguito alcune topologie di rete dei Laboratori Cisco Disponibili:
Dettagli del corso
Prerequisiti
Si consiglia la partecipazione al Corso Cisco DCCOR.
Durata del corso
- Durata Intensiva 5gg;
Frequenza
Varie tipologie di Frequenza Estensiva ed Intensiva.
Date del corso
- Corso Cisco DCAI (Formula Intensiva) – Su Richiesta – 09:00 – 17:00
Modalità di iscrizione
Le iscrizioni sono a numero chiuso per garantire ai tutti i partecipanti un servizio eccellente.
L’iscrizione avviene richiedendo di essere contattati dal seguente Link, o contattando la sede al numero verde 800-177596 o inviando una richiesta all’email [email protected].